KEDA
概述
KEDA全称为 Kubernetes Based Event Driven Autoscaler,基于事件驱动的 Kubernetes 自动伸缩)。其宗旨为Application autoscaling made simple, 即简化应用的自动伸缩。KEDA 作为 Kubernetes 的一个扩展组件,能够根据外部事件源(如消息队列、数据库指标等)动态调整 Kubernetes 工作负载的副本数,实现按需扩展和收缩。KEDA是HPA的增强版,支持更多的事件源和更复杂的扩缩容逻辑(例如定时扩缩容)。
工作原理
KEDA 通过以下几个核心组件实现其功能:
- Operator:KEDA Operator 负责管理 KEDA 的生命周期,包括部署、升级和监控等。
- Scaler:KEDA 支持多种事件源的 Scaler,如 Kafka、RabbitMQ、Azure Queue 等。每个 Scaler 负责监控特定的事件源,并根据预定义的指标触发扩缩容操作。
- Metrics Server:KEDA 使用 Kubernetes 的 Metrics Server 来获取集群内的资源使用情况,并结合外部事件源的指标来决定是否进行扩缩容。
- Custom Resource Definitions(CRDs):KEDA 定义了一些 CRD,如 ScaledObject 和 ScaledJob,用于描述需要自动伸缩的工作负载及其扩缩容策略。
- External Event Sources:KEDA 可以与多种外部事件源集成,如消息队列、数据库等,以获取触发扩缩容的指标。
其架构如下所示:
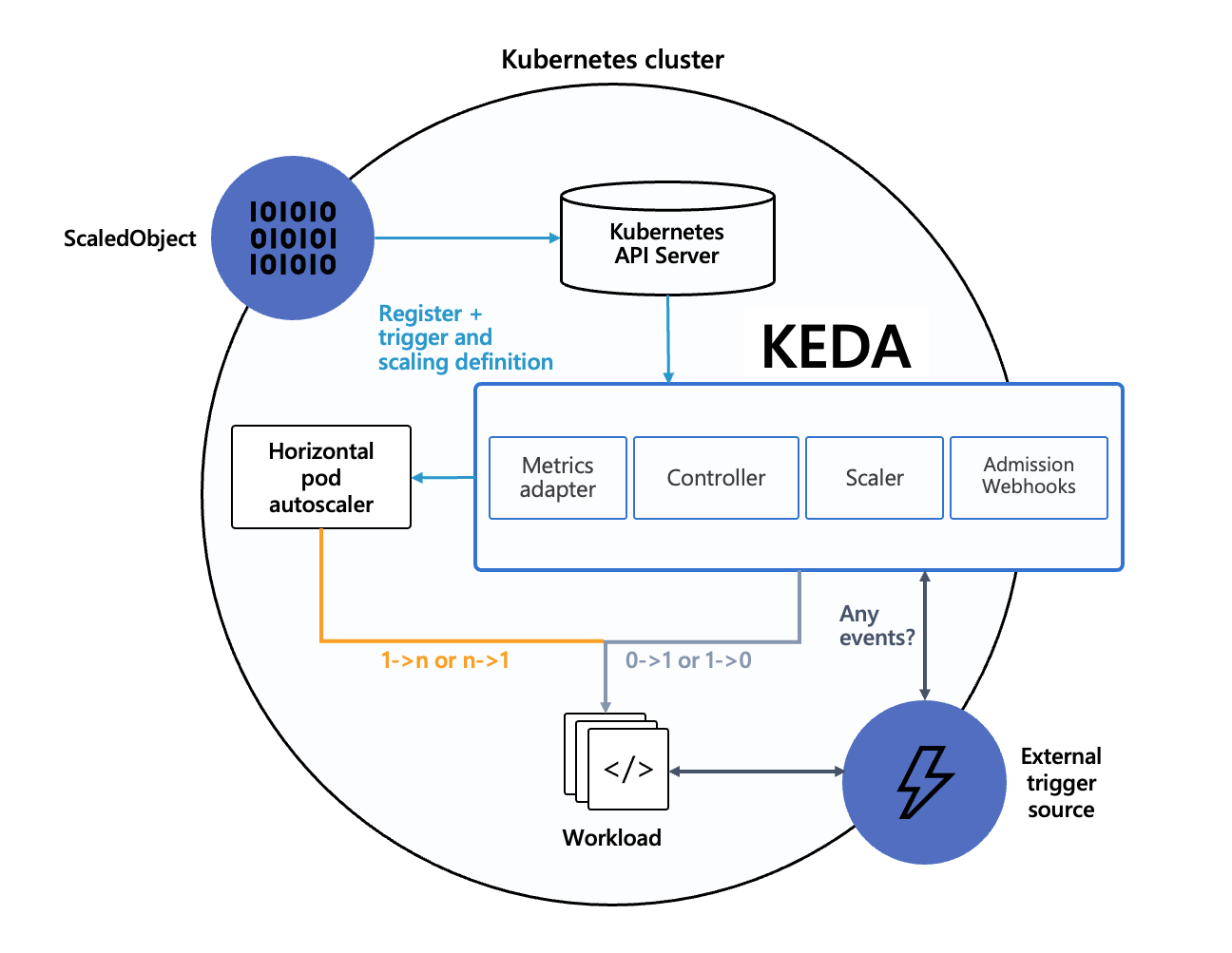
KEDA 将各种外部事件转换为所需的 External Metrics 数据,最终实现 HPA 通过 External Metrics 数据进行自动伸缩,直接复用了 HPA 已有的能力,如果想要控制扩缩容的高阶行为细节(比如快速扩容,缓慢缩容),可以通过 advanced 部分配置 HPA 的 behavior 字段来实现。
安装部署
KEDA 可以通过多种方式进行安装,其安装部署较简单,只需要创建CRD、部署Operator及 Metrics Server 等组件即可,最常见的方法是使用 Helm Chart 或直接应用官方提供的 YAML 文件。 部署前应先参考Kubernetes Compatibility查看当前 KEDA 版本兼容的 Kubernetes 版本。
本文基于 K8S 1.30.6 环境安装,因此选择 v2.17 版本,其最新的稳定版本为 v2.17.3,安装命令如下:
~ kubectl apply --server-side -f https://github.com/kedacore/keda/releases/download/v2.17.3/keda-2.17.3.yaml
namespace/keda serverside-applied
customresourcedefinition.apiextensions.k8s.io/cloudeventsources.eventing.keda.sh serverside-applied
customresourcedefinition.apiextensions.k8s.io/clustercloudeventsources.eventing.keda.sh serverside-applied
customresourcedefinition.apiextensions.k8s.io/clustertriggerauthentications.keda.sh serverside-applied
customresourcedefinition.apiextensions.k8s.io/scaledjobs.keda.sh serverside-applied
customresourcedefinition.apiextensions.k8s.io/scaledobjects.keda.sh serverside-applied
customresourcedefinition.apiextensions.k8s.io/triggerauthentications.keda.sh serverside-applied
serviceaccount/keda-operator serverside-applied
role.rbac.authorization.k8s.io/keda-operator serverside-applied
clusterrole.rbac.authorization.k8s.io/keda-external-metrics-reader serverside-applied
clusterrole.rbac.authorization.k8s.io/keda-operator serverside-applied
rolebinding.rbac.authorization.k8s.io/keda-operator serverside-applied
rolebinding.rbac.authorization.k8s.io/keda-auth-reader serverside-applied
clusterrolebinding.rbac.authorization.k8s.io/keda-hpa-controller-external-metrics serverside-applied
clusterrolebinding.rbac.authorization.k8s.io/keda-operator serverside-applied
clusterrolebinding.rbac.authorization.k8s.io/keda-system-auth-delegator serverside-applied
service/keda-admission-webhooks serverside-applied
service/keda-metrics-apiserver serverside-applied
service/keda-operator serverside-applied
deployment.apps/keda-admission serverside-applied
deployment.apps/keda-metrics-apiserver serverside-applied
deployment.apps/keda-operator serverside-applied
apiservice.apiregistration.k8s.io/v1beta1.external.metrics.k8s.io serverside-applied
validatingwebhookconfiguration.admissionregistration.k8s.io/keda-admission serverside-applied
可以看到,KEDA 部署完成后会创建 keda 命名空间,并在该命名空间��下部署 RBAC、KEDA Operator、Metrics Server 以及相关的 CRD,使用--server-side参数可以避免版本冲突问题,使用服务端应用最新的配置。
注意在安装时,组件会进行证书签发,默认使用的是 cluster.local 作为集群域名,如果集群使用了自定义域名,可能会导致证书不匹配的问题,可以参考官方文档进行配置,并同时指定metrics-service-address参数来配置 Metrics Server 的gRPC访问地址
如果是使用 Helm 进行安装,可以在 values.yaml 文件中配置相关参数
global:
image:
registry: hub.ssgeek.com
clusterName: cluster.ssgeek
clusterDomain: cluster.ssgeek
扩缩容配置
使用较多的CR为ScaledObject,它用于定义需要自动伸缩的工作负载及其扩缩容策略,除此之外还有ScaledJob用于定义按需扩缩容的批处理任务
可以参考官方示例来了解 ScaledObject 的使用方法。下面列举几个常见的扩缩容场景:
完整的参考示例如下:
# KEDA ScaledObject 完整示例(多触发器 + 全量配置语法)
# 参考: https://keda.sh/docs/2.18/reference/scaledobject-spec/
#
# 多触发器时副本数取「各指标所需副本数的最大值」:
# - Kubernetes HPA:多指标时对每个指标算出一个 desired replica count,再取其中最大值。
# https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: example-app
namespace: sre
# annotations:可选。省略时无转移 HPA、不关闭校验、不暂停扩缩。按需取消注释:
# annotations:
# scaledobject.keda.sh/transfer-hpa-ownership: "true" # 将已有 HPA 所有权转移给本 ScaledObject
# validations.keda.sh/hpa-ownership: "true" # 禁用 HPA 所有权校验
# autoscaling.keda.sh/paused: "true" # 暂停自动扩缩容
spec:
# ---------- scaleTargetRef:要扩缩的目标资源 ----------
scaleTargetRef:
apiVersion: apps/v1 # 可选,默认 apps/v1;StatefulSet 或自定义 CR 时需指定
kind: Deployment # 可选,默认 Deployment
name: example-app # 必填,须与 ScaledObject 同命名空间
# envSourceContainerName: app # 可选,从该容器读取环境变量(如密钥),默认第一个容器
# ---------- 轮询与冷却 ----------
pollingInterval: 30 # 可选。默认值:30。检查各触发器的间隔(秒)。
cooldownPeriod: 300 # 可选。默认值:300。最后一次活跃后等待多少秒再缩容到 0;仅缩到 0 时生效。
initialCooldownPeriod: 0 # 可选。默认值:0。创建后延迟多少秒再开始 cooldownPeriod;0 表示立即开始。
# ---------- 副本数 ----------
# idleReplicaCount: 0 # 可选。省略时不启用“空闲副本数”;无活跃时缩到 minReplicaCount。取值须 < minReplicaCount,HPA 限制仅支持 0。
minReplicaCount: 1 # 可选。默认值:0(可缩容到 0)。
maxReplicaCount: 20 # 可选。默认值:100。会传给 KEDA 创建的 HPA。
# ---------- fallback:scaler 持续失败时的降级副本数(CPU/Memory 触发器不支持)----------
# 【不填 fallback 时】某 scaler 连续取不到指标时,KEDA 不会向 HPA 传该指标的�归一化值(默认错误行为),
# 即该触发器“不参与”当次扩缩:HPA 只根据其他仍正常的触发器算副本数;若所有触发器都失败,则无法
# 得到新目标副本数,一般保持当前副本数不变。不会主动缩到 0 或扩到某固定值。
#
# 【配置 fallback 时】连续失败超过 failureThreshold 次后,改为向 HPA 传归一化指标,使副本数调整到
# 由 behavior 决定的降级副本数(见下),避免“指标源挂了就完全无法扩缩”或副本数悬空。
# 参考: https://keda.sh/docs/2.18/reference/scaledobject-spec/#fallback
# fallback:
# failureThreshold: 3 # 必填。scaler 连续失败超过此次数后启用 fallback
# replicas: 6 # 必填。与 behavior 共同决定降级时的目标副本数(见下)
# behavior: static # 可选,默认 "static"。决定“最终使用的 fallback 副本数”如何计算:
#
# 【static】不写或写 "static"
# 最终副本数 = fallback.replicas。
# 示例:replicas=6, behavior=static → Prometheus 连续失败 3 次后,始终扩缩到 6 副本。
#
# 【currentReplicas】
# 最终副本数 = 当前实际副本数(保持现状、不因 fallback 再扩缩)。
# 示例:当前 8 副本,Prometheus 连续失败 3 次 → 仍按 8 副本(replicas 值被忽略)。
#
# 【currentReplicasIfHigher】
# 最终副本数 = max(当前副本数, fallback.replicas)。当前更高则保持当前,否则用 replicas。
# 示例:replicas=3, 当前 6 副本 → 降级时 6 副本;当前 2 副本 → 降级时 3 副本。
#
# 【currentReplicasIfLower】
# 最终副本数 = min(当前副本数, fallback.replicas)。当前更低则保持当前,否则用 replicas。
# 示例:replicas=6, 当前 3 副本 → 降级时 3 副本;当前 8 副本 → 降级时 6 副本。
# ---------- advanced:高级选项,可选 ----------
# 参考: https://keda.sh/docs/2.18/reference/scaledobject-spec/#advanced
# advanced:
# # --- restoreToOriginalReplicaCount ---
# # 可选,默认 false。删除 ScaledObject 后,目标资源(Deployment/StatefulSet 等)是否恢复为“创建 ScaledObject 前”的副本数。
# # false:删除时保持当前副本数(例如已被 KEDA 扩到 10 则保持 10);true:恢复为创建前的值(例如原本 3 则恢复为 3)。
# restoreToOriginalReplicaCount: false
#
# # --- horizontalPodAutoscalerConfig:KEDA 创建的 HPA 的配置 ---
# horizontalPodAutoscalerConfig:
# # name: 创建的 HPA 资源名称,默认 keda-hpa-{scaled-object-name}
# name: keda-hpa-example-app
#
# # behavior: 传给 HPA 的扩缩行为,影响 1<->N 副本时的扩缩节奏(K8s 1.18+)。
# # 参考: https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/horizontal-pod-autoscaler-v2/#HPAScalingRules
# # policies 含义:type 为 Percent 时 value 是“当前副本数的百分比”;type 为 Pods 时 value 是“绝对 Pod 个数”。
# # 每条 policy 表示:在 periodSeconds 秒内,最多允许扩/缩 value 所表示的量。多条 policy 时由 selectPolicy(Min/Max,默认 Max)决定取哪条。
# behavior:
# scaleDown: # 缩容行为
# stabilizationWindowSeconds: 300 # 缩容稳定窗口(秒),在此窗口内取建议副本数的最大值,避免频繁缩容
# # selectPolicy: Max # 可选,多条 policy 时用哪条。Max=取允许变化最大的,Min=取最保守的;默认 Max
# policies:
# - type: Percent # Percent=按当前副本数比例;Pods=绝对 Pod 数。periodSeconds 内最多扩/缩 value,每 15 秒内最多缩容当前副本数的 100%(即最多全缩)
# value: 100
# periodSeconds: 15
# # --- type: Pods 示例:每 60 秒内最多缩容 2 个 Pod(与当前副本数无关)
# # - type: Pods
# # value: 2
# # periodSeconds: 60
# # tolerance: 0.1 # 见下方「tolerance 说明」
# scaleUp: # 扩容行为
# stabilizationWindowSeconds: 0 # 0 表示立即采用最大建议副本数,扩容更灵敏
# # selectPolicy: Max
# policies:
# - type: Percent
# value: 100
# periodSeconds: 15
# # --- type: Pods 示例:每 60 秒内最多扩容 4 个 Pod(与当前副本数无关)
# # - type: Pods
# # value: 4
# # periodSeconds: 60
# # tolerance: 0.1 # 见下方「tolerance 说明」
#
# 【tolerance 说明】可选,写在 scaleDown / scaleUp 下(与 policies 同级)。需 K8s v1.33+ 且开启 HPAConfigurableTolerance;v1.34 起 beta 默认可用。
# 含义:只有当「当前指标值/目标指标值」偏离 1.0 的程度超过 tolerance 时,HPA 才做出扩/缩容决策;否则视为在“死区”内,不改变副本数,避免小波动反复扩缩。
# - 比值 = currentMetricValue / desiredMetricValue。例如目标 CPU 75%、当前 90% → 比值 90/75=1.2。
# - tolerance 0.1(10%):不缩容除非比值 ≤ 0.9,不扩容除非比值 ≥ 1.1。未配置时集群默认约 10%。
# - tolerance 0.05(5%):不缩容除非比值 ≤ 0.95,不扩容除非比值 ≥ 1.05。
# - tolerance 0:任意偏离都扩缩,最敏感。
# 示例:目标内存 100Mi,scaleDown tolerance 0.05、scaleUp tolerance 0.01 → 实际 <95Mi 才缩容,>101Mi 才扩容。
# 参考: https://kubernetes.io/blog/2025/04/28/kubernetes-v1-33-hpa-configurable-tolerance/
#
# # --- scalingModifiers:用公式把多个触发器指标组合成一个复合指标,替代原先多条外部指标 ---
# # 使用后 HPA 只看到一条 composite-metric;formula 中引用的每个 trigger 必须设置 name。若启用了 fallback,公式仅在所有相关 trigger 健康时生效。
# scalingModifiers:
# # target: 必填。组合后的指标对应的目标值,HPA 按“当前值/ target”参与计算副本数
# target: "10"
# # activationTarget: 可选,默认 0。组合指标的“激活”阈值,用于从 0 扩到 1 的判断(External Push 类 scaler 可不受此限)
# activationTarget: "0"
# # metricType: 可选,AverageValue | Value,默认 AverageValue。该复合指标传给 HPA 时的类型
# metricType: AverageValue
# # formula: 必填。使用 expr 语法的表达式,对已拉取的各 trigger 指标做运算,返回一个数值(非布尔)。公式里用 trigger 的 name 引用,如 prometheus、cpu。
# # 语法见 https://github.com/antonmedv/expr、https://expr.medv.io/docs/Language-Definition
# formula: "prometheus + cpu" # 示例:名为 prometheus 与 cpu 的触发器指标相加
# ---------- triggers:至少一个;多触发器时 HPA 取所需副本数最大值 ----------
triggers:
# 1. Prometheus:按 PromQL 查询结果扩缩容
- type: prometheus # 必填。触发器类型,见 https://keda.sh/docs/2.18/scalers/
name: req-rate # 可选。默认值:由 type 自动生成。scalingModifiers 公式中引用时建议显式命名。
metricType: AverageValue # 可选。默认值:AverageValue。Prometheus 还支持 Value。(含义:HPA 以“每 Pod 平均目标值”来计算副本)
# useCachedMetrics: false # 可选。默认值:false
# authenticationRef: # 可选。省略时不使用 TriggerAuthentication/ClusterTriggerAuthentication。
# name: my-trigger-auth
metadata: # 必填。各 scaler 参数见 https://keda.sh/docs/2.18/scalers/
serverAddress: http://prometheus-server.monitoring.svc:8080
threshold: "100" # 超过该值则扩容
query: sum(rate(http_requests_total{namespace="sre",service="example-app"}[1m])) # 计算表达式,这里为服务级总QPS;若配合 AverageValue,HPA会按副本数折算为每 Pod 语义;若希望按总量语义直接控制,改用 metricType: Value
# query: avg(sum(rate(http_requests_total{namespace="sre",service="example-app",url!="/health"}[1m]))by(pod)) # 计算表达式,这里为pod级平均qps;更推荐显式配 metricType: Value,语义更直观(不是“再做一次avg”,而是避免把“按Pod平均值”再按每Pod目标语义解释)
# sum是为了把同一个pod的多个url路径的请求数加起来,url!="/health"是为了排除健康检查的请求数,avg是为了计算所有pod的平均qps
# 【CPU/Memory 的 metricType:Utilization | AverageValue】
# - Utilization:metadata.value 表示相对 resources.requests 的百分比(如 "70" ≈ 用满申请量的 70%)。
# - AverageValue:metadata.value 表示平均每 Pod 的绝对目标,须带单位(CPU 如 "200m",内存如 "256Mi")。
#
# 2. CPU:按 Pod/容器 CPU 利用率扩缩容(需 Metrics Server,Pod 需设 resources.requests)
- type: cpu
metricType: Utilization # 可选。默认 Utilization;与下方 value 语义见上文「CPU/Memory 的 metricType」。
metadata:
value: "70" # 必填。Utilization 时为百分比;AverageValue 时为带单位的平均每 Pod 目标。
# containerName: app # 可选。省略时:按整个 Pod(多容器为总和);指定则按该容器。
# 3. Memory:按 Pod/容器内存利用率扩缩容(需 Metrics Server,Pod 需设 resources.requests)
- type: memory
metricType: Utilization # 可选。默认 Utilization;与下方 value 语义见上文「CPU/Memory 的 metricType」。
metadata:
value: "80" # 必填。Utilization 时为百分比;AverageValue 时为带单位的平均每 Pod 目标。
# containerName: app # 可选。省略时:按整个 Pod;指定则按该容器。。
# 4. Cron:按时间窗口扩缩容(start/end 为 Linux 五段 cron:分 时 日 月 周)
- type: cron
metadata:
timezone: Asia/Shanghai # 必填。IANA 时区。时区表见 https://en.wikipedia.org/wiki/List_of_tz_database_time_zones
start: "0 6 * * *" # 必填。窗口开始时间(cron)。
end: "0 20 * * *" # 必填。窗口结束时间(cron);不可与 start 相同。
desiredReplicas: "2" # 必填。start~end 期间目标副本数(相当于该时段动态 minReplicas)。
# 当 minReplicaCount 为 0 时,窗口外会缩容到 0(受 cooldownPeriod 影响)。
# 5. Kubernetes Workload:按匹配 podSelector 的 Pod 数量与当前目标副本数的比值扩缩容(仅统计同命名空间、排除 Succeeded/Failed)
- type: kubernetes-workload
name: workload-pods # 可选。默认值:由 type 自动生成。
metricType: AverageValue # 可选。默认值:AverageValue。还支持 Value。
metadata:
podSelector: "app=backend" # 必填。Label 选择器,用于统计 Pod 数量;支持多选择器逗号分隔、set-based(如 key in (v1,v2))。
value: "2" # 必填。目标比值:(匹配 selector 的 Pod 数) / (本 ScaledObject 目标副本数);可为小数。
# activationValue: "0" # 可选。默认值:0。含义见下方「activationValue 说明」。
# 统计范围:ScaledObject 所在命名空间;排除 phase 为 Succeeded、Failed 的 Pod。无需认证参数。
#
# 【activationValue 说明】仅影响 0<->1 的“激活/停用”决策,不影响 1<->N 的扩缩(后者由 value 和 HPA 决定)。
# - 当当前副本数为 0 时:仅当指标值 > activationValue,KEDA 才认为该触发器“活跃”,才会从 0 扩到 1。
# - 当当前副本数为 1 及以上时:仅当指标值 <= activationValue,KEDA 才认为“不活跃”,才可能缩回 0(还受 cooldownPeriod 等约束)。
# - 默认 0 表示:指标值 > 0 即激活(从 0 扩到 1),指标值 <= 0 才可能缩到 0。若 minReplicaCount >= 1,激活值会被忽略。
# 参考: https://keda.sh/docs/2.18/concepts/scaling-deployments/#activating-and-scaling-thresholds
目标副本数计算规则说明
KEDA 最终是把指标交给 Kubernetes HPA 计算副本数。HPA 的核心换算规则是:
desiredReplicas = ceil(currentReplicas * (currentMetricValue / desiredMetricValue))
其中:
currentReplicas:当前副本数;currentMetricValue:当前观测指标值;desiredMetricValue:目标指标值;ceil:向上取整,保证结果为整数副本。
在指标类型上,容易混淆的点是:
- 对 CPU/内存 Resource 指标,常见目标类型是
Utilization(相对 requests 的百分比)或AverageValue。 - 对 External/Custom 指标(例如 KEDA Prometheus),常见是
AverageValue或Value;Utilization不适用于这类外部指标。
因此在本文的 QPS 场景里,如果你的 PromQL 已经是 Pod 平均 QPS,建议显式设置 metricType: Value,避免把“已按 Pod 聚合过的值”再按 AverageValue 的每 Pod 目标语义解释,导致阈值理解和扩缩容结果不准确
官方参考:
扩缩容观测
KEDA 通过创建 Kubernetes HPA 来实现自动扩缩容,因此可以使用 kubectl get hpa 命令来查看 KEDA 创建的 HPA 资源,从而监控扩缩容的状态和指标
~ kubectl get hpa
也可以通过查看ScaledObject 的状态来获取扩缩容的详细信息
~ kubectl get so
~ kubectl describe so example-app
此外,KEDA 还提供了一些 Metric指标,可以通过 Grafana大盘 进行分析,帮助用户更好地了解扩缩容的行为和效果
例如用 QPS 作为扩缩容指标时,可以通过以下 PromQL 查询服务原本的 QPS 指标:
sum(rate(http_requests_total{namespace="sre",service="example-app"}[2m]))
也可以查询 KEDA 的 ScaledObject 对应的外部指标:
sum by(metric) (keda_scaler_metrics_value{cluster=~"$cluster",exported_namespace="sre",scaledobject="example-app",metric="s0-prometheus"})
查看 KEDA 扩缩容对象的副本数时,同样可以基于原本的 PromQL 查询,也可以通过 KEDA 的指标查询:
max(sum by(instance)(kube_deployment_status_replicas{namespace="sre",deployment="example-app"}))
# 或
max(sum by(prometheus_shard)(kube_horizontalpodautoscaler_status_current_replicas{namespace="sre",horizontalpodautoscaler="keda-hpa-example-app"}))